
How does HashMap work internally in Java?
How does HashMap work internally in java is one of the most asked core java interview questions. Most of the candidates do not give the satisfactory explanation. This question shows that candidate has good knowledge of Collection. So this question should be
There are four things we should know about HashMap before going into the internals of how does HashMap work in Java.
1. Hashing
HashMap works on the principal of hashing. Hashing is the process of indexing and retrieving element (data) in a data structure to provide faster way of finding the element using the hash key.
2. Map.Entry interface / Node class
HashMap maintains an array of buckets. Each bucket is a linkedlist of a private static inner class called an Entry Class which encapsulates the key-value pairs.
static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// constructor and methods
}Bucket term used here is actually an index of array, that array is called table in HashMap implementation. Thus table[0] is referred as bucket0, table[1] as bucket1 and so on.
/**
* The table, resized as necessary. Length MUST Always be a power of two.
**/
transient Entry[] table;
3. hashCode() method
Hashcodes are typically used to increase the performance of large collections of data.
Collections such as HashMap and HashSet use the hashcode value of an object to determine where the object should be stored in the collection, and the hashcode is used again to help locate the object in the collection. lets understand this by following example.
Example:
Imagine a set of buckets lined up on the floor. Someone hands you a piece of paper with movie name on it. You take the movie name and calculate an integer code(i.e. Hashcode) for each name by calculating total number of characters in that name.
Imagine that each bucket represents a different code number (Hashcode) and place the piece of paper into corresponding bucket according to its Hashcode value.
Here, movie Gandhi has 6 letters, so we will put it into the Bucket with value 6.
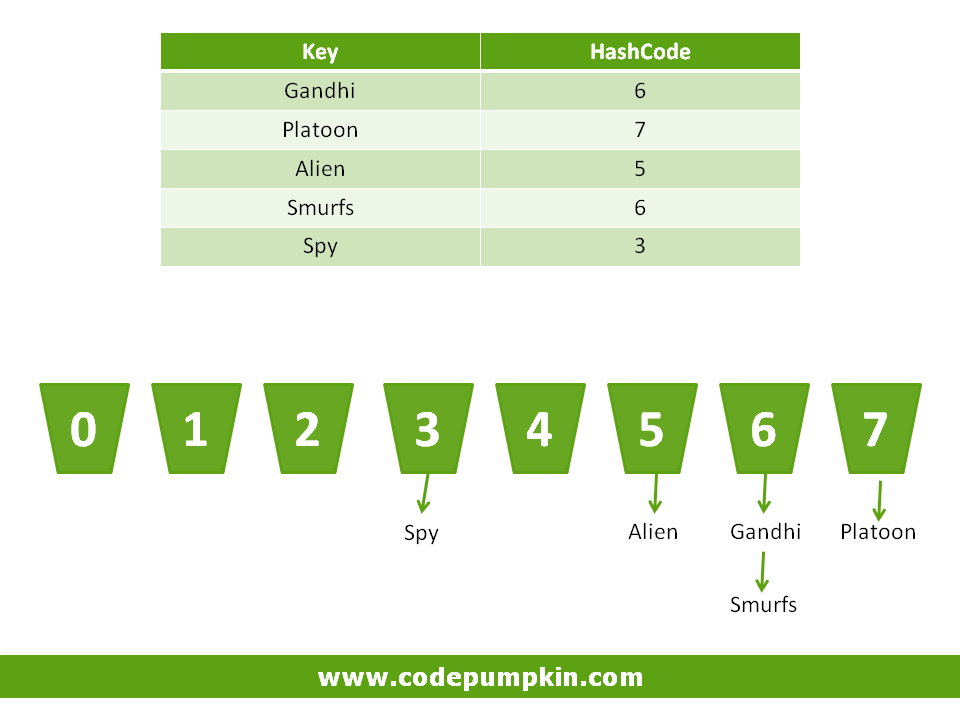
Now imagine that someone comes up and shows you a name and says, "Please retrieve the piece of paper that matches this name." So you look at the name they show you, and run the same hashcode-generating algorithm. The hashcode tells you in which bucket you should look to find the name.
4. equals() method
In above example, you might have noticed that two different names may result in the same value. Such situation is known as Hashing Collision.
For example, the movie names Gandhi and Smurfs have the same number of letters, so the hashcode will be identical
The hashcode tells you only about which bucket to go into, but not how to locate the name once we're in that bucket. In such cases, equals() method is used to locate the exact match.
So for efficiency, your goal is to have the papers distributed as evenly as possible across all buckets. Ideally, you should have just one name per bucket so that when someone asks for a paper you can simply calculate the hashcode and just grab the one paper from the correct bucket (without having to go flipping through different papers in that bucket until you locate the exact one you're looking for).
The least efficient hashcode generator returns the same hashcode for all the movie
In real-life hashing, it’s common to have more than one entry in a bucket. Hashing retrieval is a two-step process.
- Find the right bucket (using hashCode())
- Search the bucket for the right element (using equals() ).
HashMap provides put(key, value) for storing and get(key) method for retrieving Values from HashMap.
How put() method works internally?
- Using hashCode() method, hash value will be calculated. Using that hash it will be ascertained, in which bucket particular entry will be stored.
- equals() method is used to find if such a key already exists in that bucket, if no then a new node is created with the map entry and stored within the same bucket. A linked-list is used to store those nodes.
- If equals() method returns true, which means that the key already exists in the bucket. In that case, the new value will overwrite the old value for the matched key.
In case of null Key
As we know that HashMap also allows null, though there can only be one null key in HashMap. While storing the Entry object HashMap implementation checks if the key is null, in case key it is null, it always maps it to bucket 0 as hash is not calculated for null keys.
How get() method works internally?
- Using the key again, hash value will be calculated to determine the bucket where that Entry object is stored.
- In case there are more than one Entry objects are stored within the same bucket as a linked-list, equals() method will be used to find out the correct key.
- As soon as the matching key is found, get() method will return the value object stored in the Entry object.
HashMap changes in Java 8
Though HashMap implementation provides constant time performance O(1) for get() and put() method, but that is in the ideal case when the Hash function distributes the objects evenly among the buckets.
The performance may worsen in the case hashCode() is not proper and there are lots of hash collisions. As we know that in case of hash collision entry objects are stored as a node in a linked-list and equals() method is used to compare keys. That comparison to find the correct key within a linked-list is a linear operation so in a worst case scenario the complexity becomes O(n).
To address this issue in Java 8 hash elements use balanced trees instead of linked lists after a certain threshold is reached. Which means HashMap starts with storing Entry objects in linked list, but after the number of items in a hash becomes larger than a certain threshold, the hash will change from using a linked list to a balanced tree. This improves the worst case performance from O(n) to O(log n).
That's all for this topic. If you guys have any suggestions or queries, feel free to drop a comment. We would be happy to add that in our post. You can also contribute your articles by creating contributor account here.
Happy Learning 🙂
If you like the content on CodePumpkin and if you wish to do something for the community and the planet Earth, you can donate to our campaign for planting more trees at CodePumpkin Cauvery Calling Campaign.
We may not get time to plant a tree, but we can definitely donate ₹42 per Tree.
About the Author












Tags: Collection Framework, Collections, Core Java, equals, HashCode, HashMap, Java, Java8
Comments and Queries
If you want someone to read your code, please put the code inside <pre><code> and </code></pre> tags. For example:<pre><code class="java"> String foo = "bar"; </code></pre>For more information on supported HTML tags in disqus comment, click here.